UpKeep AI Suggestion
Search Results
Blog Post
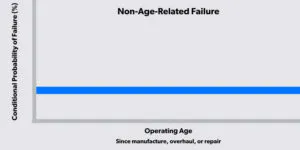
How to Address Non-Age Related or Random Equipment Failure
Learn how to identify and resolve non-age-related and random equipment failures in this article by maintenance expert Jim Borowski.
Published on December 10, 2018


Loading...
Want to keep reading?
Good choice. We have more articles about maintenance!
4,000+ COMPANIES RELY ON ASSET OPERATIONS MANAGEMENT
Leading the Way to a Better Future for Maintenance and Reliability
Your asset and equipment data doesn't belong in a silo. UpKeep makes it simple to see where everything stands, all in one place. That means less guesswork and more time to focus on what matters.












